After fully embracing cloud-native technology, Chainbase has officially launched and is hosting over 100+ core dataset subgraphs: https://console.chainbase.com/indexer
1. Background
For projects with complex smart contracts like Uniswap(Defi) or Bored Ape Yacht Club(NFT) , all their data is stored on the blockchain. Direct interactions with the blockchain only allow us to extract basic contract data. For instance, we can use eth_call to find the owner of a specific Bored Ape, retrieve the content URI of the ape based on its ID, or determine the total supply.
However, we're unable to perform more advanced operations like aggregation, searching, or relational queries. For example, if we want to find out which apes a certain address owns and filter them based on a specific trait, we can't get this information directly by interacting with the on-chain contract.
To access this information, we need to develop a backend program that begins processing all transfer events emitted by the contract, starting from block height zero. This program uses the Token ID and IPFS hash to fetch the metadata from IPFS. Only after summarizing and calculating this data can we derive the information that developers desire. This backend program is what we call a Subgraph.
A Subgraph is a specific implementation of The Graph's decentralized application indexing protocol. It serves as an indexing engine for various smart contracts, providing datasets for developers to query swiftly and efficiently.

2. Challenges
As the blockchain ecosystem evolves, building Subgraphs has become a favorite tool among developers for accessing and providing blockchain data. Each Subgraph corresponds to a specific smart contract, leading to an increase in the number of Subgraphs that need to be built and hosted to meet the needs of different users and scenarios. We have managed to host and support most of the core Subgraphs in the ecosystem, with datasets being the most hosted component.
Yet, this scaling of hosting has introduced numerous problems and challenges to the existing framework and operation methods:
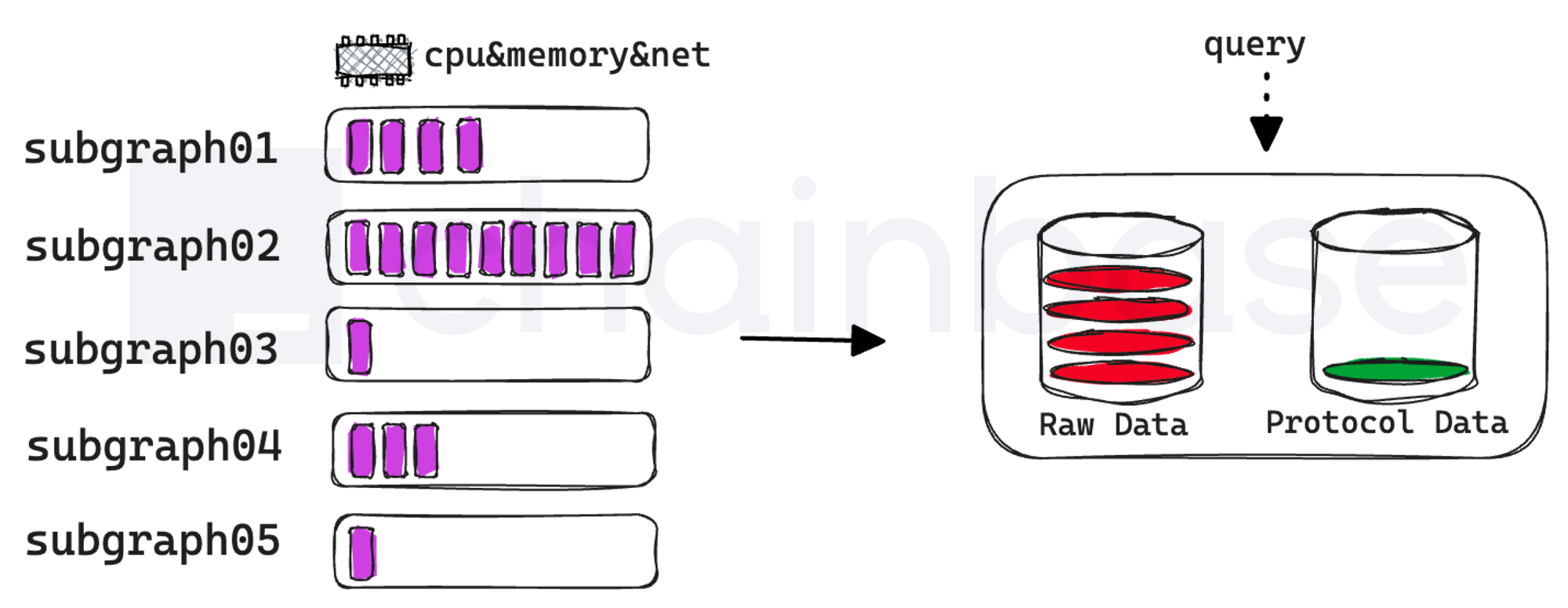
2.1 Monolithic PostgreSQL Database with Large Cache, No Read-Write Separation
By default, Graph Node uses PostgreSQL as the backend relational database, with all subgraphs sharing a single database instance. It also forcibly caches on-chain Raw Data according to the specified chains.provider in the configuration, which cannot be turned off.
In configurations with multiple providers, most of the database space will be occupied by Raw Data, necessitating constant database instance capacity and IOPS expansion. The most fatal issue is that as the database instance capacity increases, the overall read-write performance of the database significantly decreases. Eventually, a separate read-only database instance has to be launched for query request reading to reduce latency. If each subgraph starts an instance, it will face the problem of each database caching a complete set of Raw Data, leading to serious data redundancy and resource waste.

2.2 Subgraph Tasks Prone to Resource Preemption, Difficult to Scale Resources
When a Subgraph is first deployed, it starts indexing from the set startBlock. As the initial contract transactions are relatively small, the indexing speed is relatively fast and consumes fewer resources. But as it reaches the core transaction blocks, the transaction volume increases, and the number of events grows. This leads to slower indexing and higher resource consumption.The resources available for a single-node Graph Node deployment are determined by the hardware specifications of the machine it's installed on. Just like any software, the Graph Node's maximum capabilities are bound by the hardware resources of this machine, including its processing power, memory, and storage.
Utilization rate of these physical machine resources often experiences peaks and troughs. This can lead to an inability to scale up in time when the Subgraph needs resources, and an inability to scale down when the Subgraph has indexed to the latest block and does not need many resources.
2.3 Subgraph Tasks Prone to Resource Preemption
In the same node, multiple subgraphs are deployed together, and the subgraph's all debug, info, warn, error logs are mixed together, making it difficult to accurately judge which subgraph the error log belongs to.
2.4 The Need for Stable, High-Performance RPC Nodes
The indexing performance of a subgraph largely depends on the communication performance of the RPC nodes. The lower the latency of the RPC node requests, the faster the indexing speed of the subgraph, and the shorter the time it takes for newly deployed subgraph data to catch up to the latest block. However, the cost of deploying RPC nodes oneself is high.
3. Chainbase's Solution Approach

3.1 Separation of Storage and Computation, and PostgreSQL Database Cluster
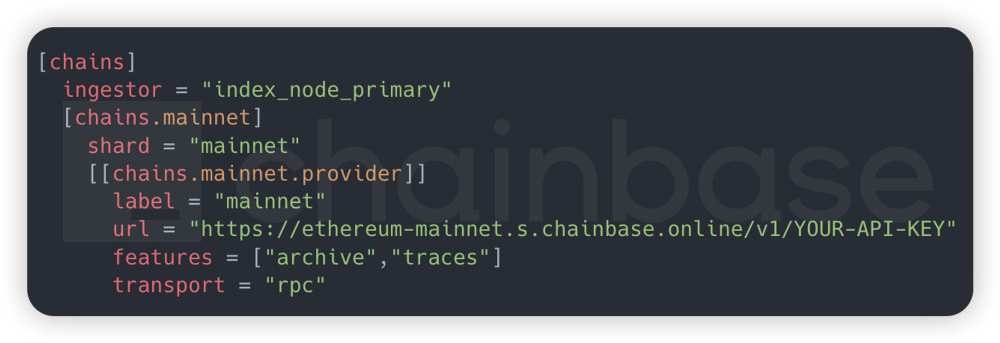
To allow for independent scaling of computation and storage and to enhance system flexibility, we need to distinguish between the database of each subgraph and the Raw Data Cache on each chain. For example, ethereum and polygon should each have a separate database instance. When a new subgraph is deployed, we detect which public chain subgraph it belongs to and automatically assign the corresponding Cache connection address.
The advantage of this approach is that we only need to maintain a global Cache data set, eliminating the need for each subgraph to cache Cache data. A single Cache can be shared by all other subgraphs, solving the problem of data redundancy.
Secondly, we can use pvc in kubernetes to expand resources for each separate database instance. The scale of each expansion can be finely controlled according to the growth rate of the subgraph index data volume and its indexing progress. This way, we can clearly predict the total resources required by the subgraph.


3.2 Subgraph Resource Isolation and Automatic Scaling
Each subgraph is abstracted into a stateless application using deployment, which connects to the stateful postgresql database instance in the backend via statefulset, effectively isolating the computation, storage, and network resources of each subgraph.
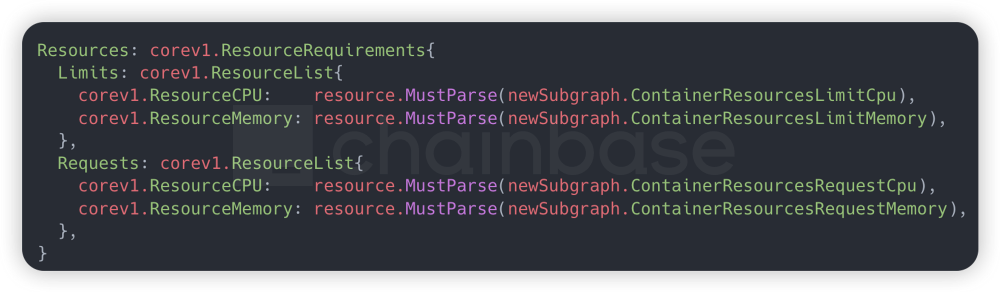
A global initial resource request and limit are set for the subgraph. Within the limit, the subgraph is allowed to dynamically adjust resources. When resource utilization reaches over 80%, it scales up; when utilization is below 30%, it scales down.
However, since the current version of subgraph can only run in a single thread and does not support parallel indexing, traditional Horizontal Pod Autoscaler (HPA) horizontal scaling cannot improve indexing speed. Instead, Vertical Pod Autoscaler (VPA) vertical scaling is used to dynamically increase the resource limit, achieving the desired indexing performance for the subgraph.
3.3 Metrics Monitoring and Log Collection
Thanks to the resource isolation feature of subgraph in kubernetes after containerization, we can collect specific monitoring metric data for each subgraph based on specific pods. We use kube-metrics to collect cluster data uniformly, which is used for subgraph stability monitoring, alerting, and dynamic resource scaling. At this point, we can enable debug logs and use elastic for unified collection, exposing an API that allows for easy querying of debug log information for each subgraph.
3.4 Stable, High-Performance RPC Nodes
RPC nodes need to support high concurrency, high availability, and low latency, and also need to provide stable SLA services. Self-hosting and deploying RPC nodes not only have high hardware costs, but the nodes are also difficult to maintain and optimize in the later stage. Choosing a stable RPC service provider is a basic guarantee for subgraph indexing.
4. Benefits and Effects
In traditional deployment architectures, if we need to deploy an Ethereum archive node, the current best choice is to use the Erigon client. However, the minimum hardware resource configuration required (referencing AWS cloud resource instance i4i.4xlarge) is:

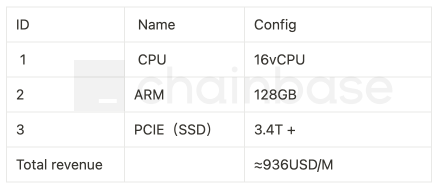
By using the RPC service from Chainbase, you only need to subscribe to the basic package, saving over 90% of the cost.
Moreover, after hosting subgraph in the cloud-native environment, we have solved the indexing performance and cache resource redundancy issues caused by the database bottleneck in the monolithic architecture. With the help of the kubernetes ecosystem, we have addressed the dynamic scaling of resources, which, in combination with the subgraph indexing resource requirements, has significantly improved resource utilization.
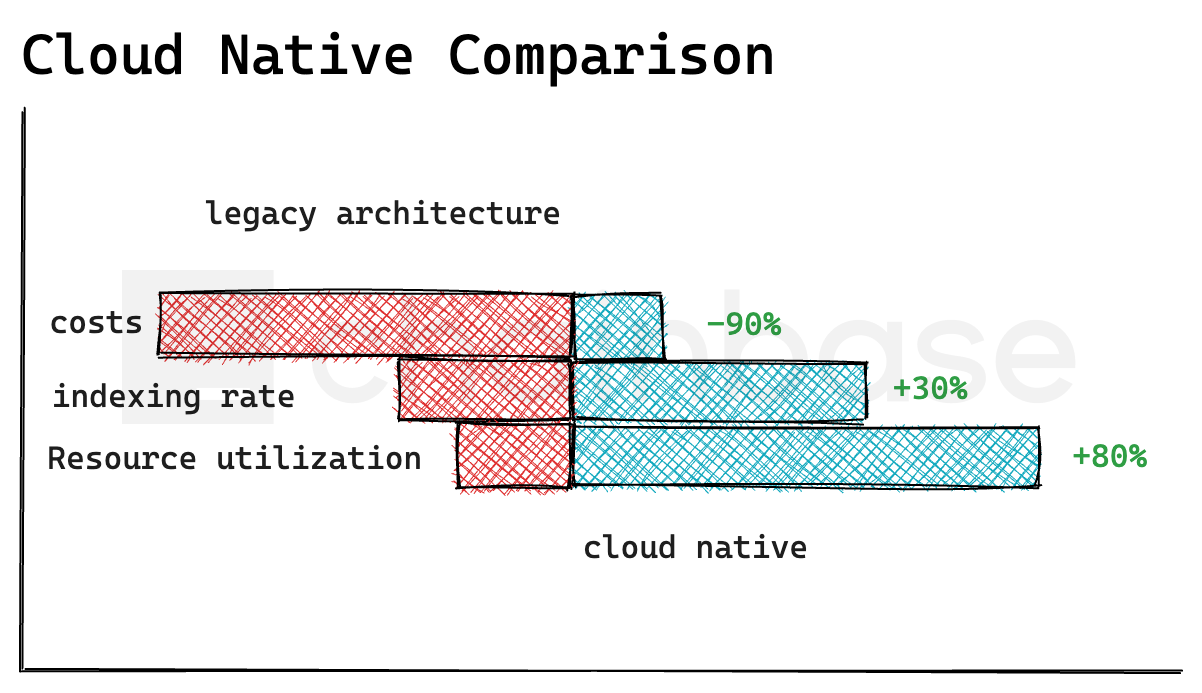
- Indexing speed has increased by over 30% due to improvements in RPC node and database read/write performance.
- The average resource utilization of subgraphs has increased by 80%.
5. The Future
Given the inherent limitation of subgraphs only being able to index blocks sequentially, we are currently unable to significantly increase the speed of indexing a brand new subgraph from scratch. Chainbase is actively seeking ways to break through these technical constraints, such as supporting efficient streaming engines like Firehose and Substream, so that we can further accelerate the speed of subgraph indexing. We will continue to refine our products to meet customer needs and make meaningful contributions to the development of the entire industry. We look forward to exploring this future full of possibilities together with all our customers and partners.
About Chainbase
Chainbase is an all-in-one data infrastructure for Web3 that allows you to index, transform, and use on-chain data at scale. By leveraging enriched on-chain data and streaming computing technologies across one data infrastructure, Chainbase automates the indexing and querying of blockchain data, enabling developers to accomplish more with less effort.
Want to learn more about Chainbase?
Visit our website chainbase.com Sign up for a free account, and Check out our documentation.
Website|Blog|Twitter|Discord|Link3










