In Web3, it seems that as long as the project is focused on building infra, it is considered solid. But what does infra mean in the Web3/Blockchain/Crypto field?
You may have heard about chains, oracles, protocols, etc., and yet they are infra in the general sense, but how to categorize them?
First, let’s take a step back to look at the essence of blockchain tech.
Blockchain is a global distributed ledger with encrypted blocks of sequentially linked data. Essentially, it is used to record transactions and store data in a transparent and immutable way. At first, Bitcoin, taking advantage of the decentralized tech, was invented and since then operates independently of the central bank system. Later, Ethereum, developed on the basis of Bitcoin, was introduced and allows smart contracts and applications (not just transactions) to be deployed on the blockchain.
Currently, we have different types of blockchains:
-
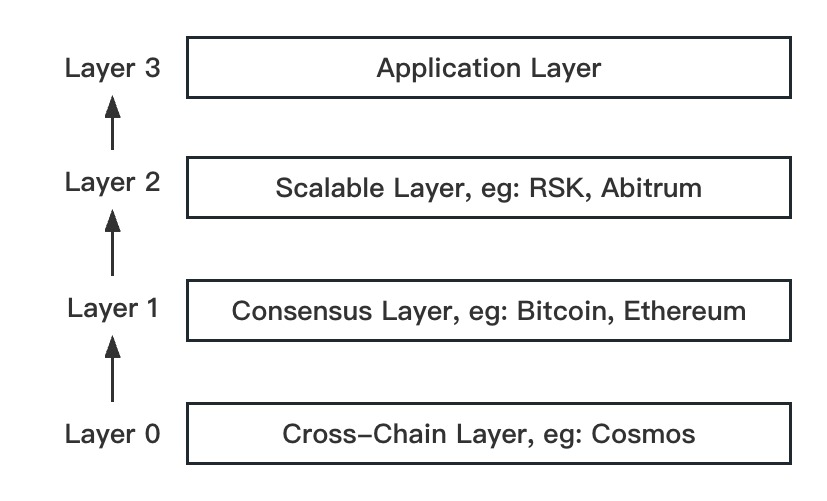
Layer 1 and Layer 2. Layer 1 stands for the base blockchain networks like Bitcoin, Ethereum, etc., and functions as the consensus layer. Layer 2 solves the scaling issue with Layer 1s by moving computation off-chain. e.g. RSK (Layer 2 of Bitcoin) and Arbitrum (Layer 2 of Ethereum). Recently, Layer 0 and Layer 3 are also introduced. Layer 0 protocol enables multiple Layer 1s to be built and connected with each other. e.g. Cosmos, aiming to be the Internet of Blockchain. Layer 3 allows protocol-level data transfers cross-chain so that multi-chain applications can function more seamlessly. It is usually the layer that hosts dApps.
-
EVM v.s. nonEVM. EVM stands for Ethereum Virtual Machine. The virtual machine is on top of the hardware layer and node network layer, and (E)VM is used to execute (Solidity-based) smart contracts. There are two types of EVM: EVM compatible (Polygon, BSC, Avalanche, etc.) and EVM equivalent (Optimism, Filecoin, etc.). Major nonEVM chains include Solana (Rust-based), Sui (Move-based), etc.
-
Modular v.s. Monolithic. Modular blockchains like Celestia (data availability layer) and Fuel (execution layer) are often focused on specific tasks (consensus, execution, data availability, or settlement) and outsource the rest to other layers. Most Layer 1s are monolithic blockchains.
-
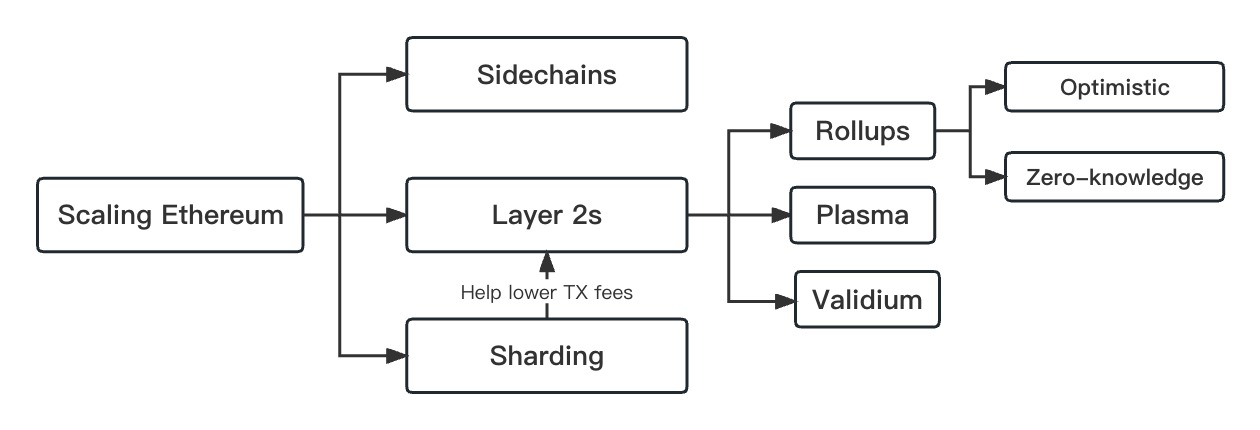
Scaling solutions. Scaling Ethereum - to design a mechanism that supports higher TPS (Transaction per second) without sacrificing functionality - for future mass adoption has been an issue since its inception. Common solutions now include Sidechains (e.g. Polygon), Layer 2, and Sharding. And Layer 2 further consists of Rollups (Optimistic rollup e.g. Optimism, and Zero-knowledge rollup e.g. StarkNet), Plasma (e.g. OMG Plasma), Validium (e.g. Immutable X), etc. The major difference between Sidechains and Layer 2 is that the latter’s security is guaranteed by Ethereum while the former has its own consensus mechanism. Sharding is a popular topic right now and it actually helps Layer 2 Rollups lower transaction fees by spreading the load of Rollups handling the data.
-
Public v.s. Private v.s. Consortium. Public Blockchain (e.g. Ethereum) is a non-restrictive form of the ledger that allows anyone who has access to the blockchain to participate. There is no single authority that controls the state of the blockchain. Private Blockchain operates in smaller contexts with a single entity controlling the whole parameters. It usually runs within a small organization (a firm or an organization) or a closed network and best suits for internal use. Consortium Blockchain or Federated Blockchain (e.g. Hyperledger) has advantages of both public and private blockchain. Unlike Public Chain, Consortium Blockchain is not open to everyone, it allows few pre-selected participants to participate and grants each participant equal power. Therefore, a consortium blockchain is best suited for consensus-building between organizations. While is much more performant than a public chain, it is less decentralized.
Extending the concept of blockchain, we have on-chain, off-chain, multi-chain, and cross-chain.
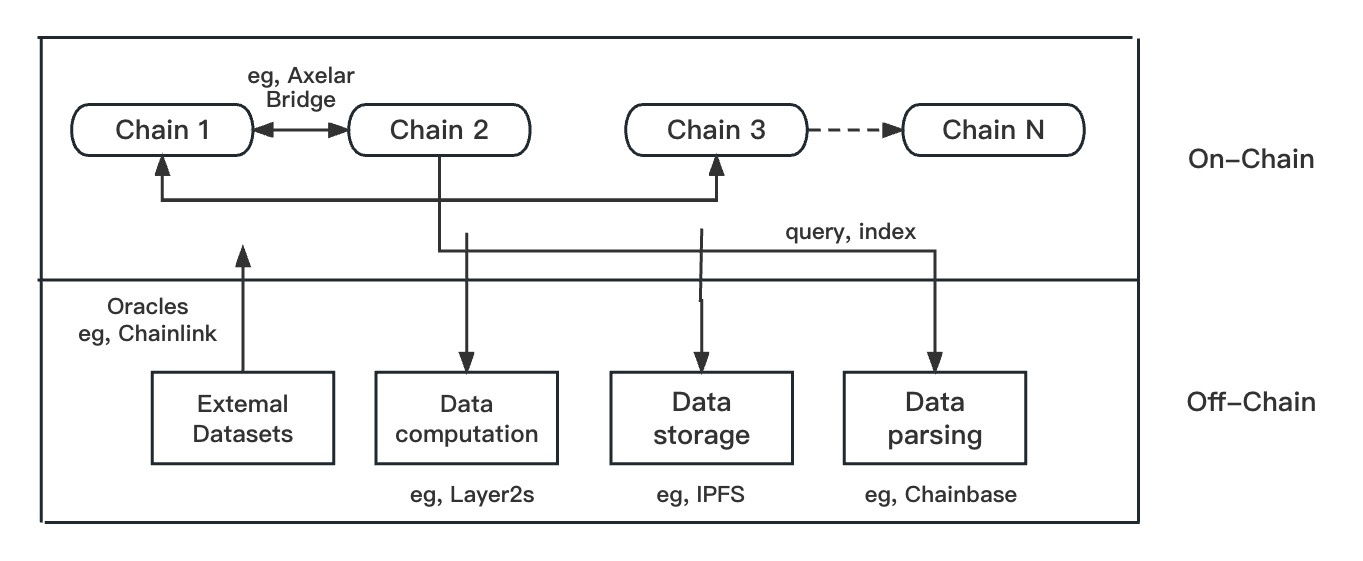
Off-chain data storage:
To store data on-chain is computation-intensive, costly, and sometimes meaningless. That’s why we need off-chain data storage that is also decentralized, such as IPFS and Arweave. Of course, you can store data in centralized databases as well, it’s just a matter of personal preference: stability, security, etc.
Also, there is off-chain data computation, which is taken over by most Layer 2s, so we don’t include it here.
On-chain off-chain data transfer:
To bridge between on-chain and off-chain, or in general, to connect blockchains to external systems - because blockchain is designed in a way that it cannot request data from the outside - we need oracles. The point of bringing data on-chain is to make the data immutably stored, publicly verifiable, and thus valuable. Oracles like Chainlink are often used to pull data on-chain. In most scenarios, it will be price data from centralized exchanges, US stocks, etc. fed to DeFi protocols. Some other interesting use cases include pulling geospatial data on-chain to automatically execute specific smart contracts.
Cross-chain data exchange:
Whether the future is multi-chain is still debatable. But for now, although Ethereum and EVM chains take the lead in terms of TVL (Total Value Locked, often used to evaluate a chain’s popularity), nonEVM ecosystems also grow out of differentiated advantages and they often have the need to communicate with other EVM chains. Top cross-chain interoperability protocols include Axelar, Wormhole, Bridge to Arbitrum, etc.
On-chain data query, index, and parse:
Last but not the least, we have the infra that is related to on-chain. Connecting to the blockchain networks (via nodes) and accessing blockchain data is not an easy task and certain middleware is needed. Because blockchain employs the linked-list data structure, fetching and parsing data also differs from that in normal databases. As a result, we have node providers (e.g. Alchemy, QuickNode), data indexers (e.g. Moralis, The Graph), and analytics platforms (e.g. Dune, Nansen). However, most of them provide users with fixed APIs instead of API custom capability (to enable it, an open database should serve as the basis). Also, the data is not indexed in real-time, often with unsatisfying stability and integrity. Right now, more and more teams have noticed the need to serve up on-chain data in a reliable and efficient way and put forward respective solutions.
Chainbase falls into this area. We believe that the Web3 future is about better data utilization and developers are the ones to build dApps and bring billions of users into the blockchain world.
That’s why we take the developer-centric approach and build the real-time data infra for Web3 where users can easily and freely query and index on-chain data via pre-defined as well as custom APIs, thus saving time and energy spent on the backend, and fully focusing on the product.
About Chainbase
Chainbase is an all-in-one data infrastructure for Web3 that allows you to index, transform, and use on-chain data at scale. By leveraging enriched on-chain data and streaming computing technologies across one data infrastructure, Chainbase automates the indexing and querying of blockchain data, enabling developers to accomplish more with less effort.
Want to learn more about Chainbase?
Visit our website chainbase.com Sign up for a free account, and Check out our documentation.
Website|Blog|Twitter|Discord|Link3









